特斯拉的一张芯片图片引发猜想:台积电InFO_SoW的首次实现?
最近世界知名的机器人和自动驾驶研究员丹尼斯-洪(Dennis Hong)发布的一张图片引发了广泛猜想。Dennis Hong 教授,在加州大学洛杉矶分校经营一个大型实验室。他的推文配了一张用于机器人和自动驾驶的图片。文字只写了特斯拉人工智能日,以及8月19日的日期、时间和活动的地点。


考虑到特斯拉刚刚建造了可能被一些人认为是世界第三大的超级计算机,这个时机相当有趣。那是用Nvidia的GPU和Super Micro Systems建造的。
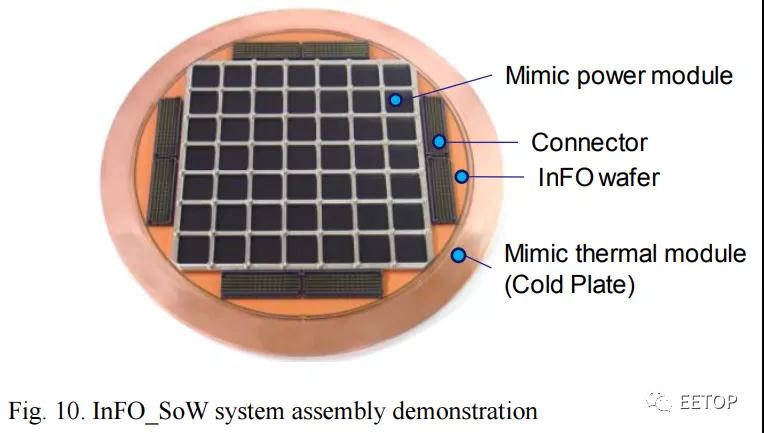
乍一看,它看起来有一个载体、散热片和电源传输。当然,最有趣的部分是芯片。它有一个大的BGA焊盘阵列和一个5×5的芯片阵列。这种类型的封装看起来令人难以置信的非正统,我们唯一能想到的是台积电的晶圆上集成扇出系统技术InFO_SoW (System-on-Wafer)。以下是该论文在IEEE上的链接。
https://ieeexplore.ieee.org/document/9159219
这张图片看起来与特斯拉的芯片非常相似,并提供了一些见解。就像特斯拉的图片一样,有一个冷板。各种芯片排列成一个网格,一个InFo Wafer,还有连接器。这些结构看起来是1比1的匹配,但它们的确切细节看起来与最初的台积电研究略有不同。
InFO_SoW通过作为载体本身,消除了对衬底和PCB的使用。在一个紧凑的系统内紧密包装的多个芯片阵列使该解决方案能够获得晶圆级优势,如低延迟的芯片间通信、高带宽密度和低PDN阻抗,以获得更大的计算性能和电源效率。除了异构芯片集成外,其wafer-field处理能力还支持基于小芯片的设计,以实现更大的成本节约和设计灵活性。
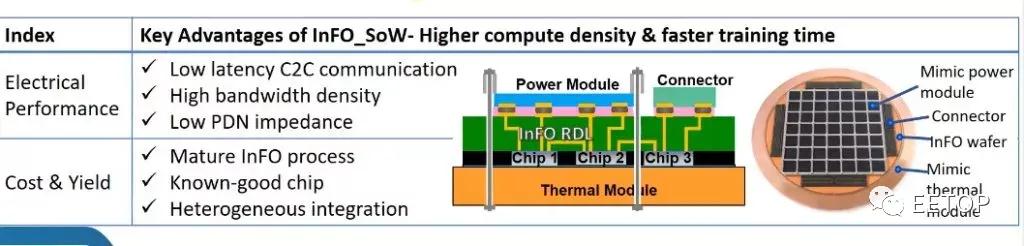
这突破了目前多芯片模块的障碍。对于基于插板的技术,如Nvidia数据中心GPU,它们受到插板制造极限的限制。台积电的第5 代 CoWoS-S 最近 ,这种方法涉及到一些制造困难,因为插板本身就是一个硅芯片。这种类型的封装在为巨大的人工智能工作负载扩展芯片数量方面具有局限性。
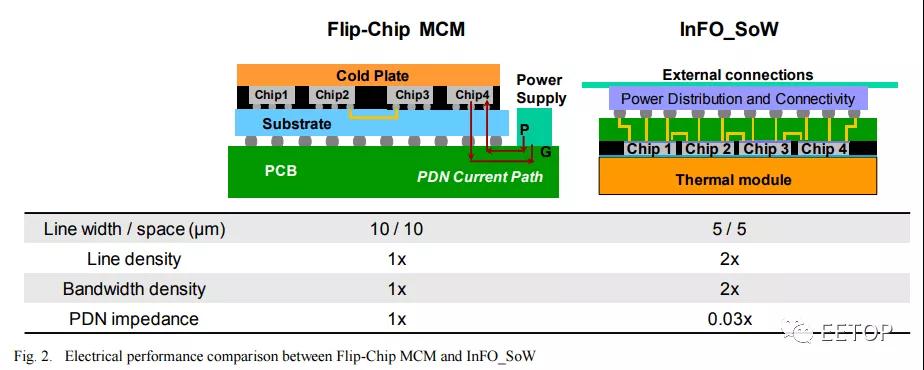
另一种方法是倒装芯片封装。最著名的采用这种封装的 MCM 设计是 AMD CPU。它们不存在reticle的限制问题,但在功率和线密度方面存在巨大缺陷。在芯片间数据传输上会消耗更多的电量,并且芯片之间的带宽是有限的。由于这些限制,这种类型的封装并不太适合规模巨大的 AI 工作负载。
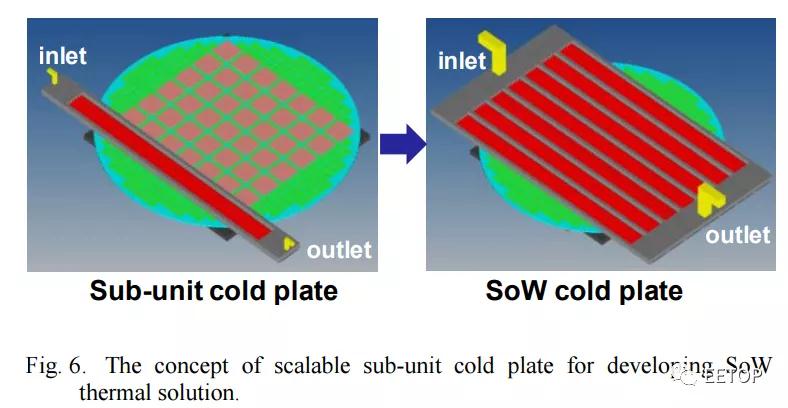
随着特斯拉希望在其 Dojo 超级计算机设计中实现的扩展,将会产生大量的热量。InFO_SoW能够提供 7,000W 的功率。相比之下,Nvidia 的数据中心 A100 GPU 的配置为 500W。这需要大量考虑冷却问题,而台积电关于InFO_SoW 上的论文提供了解决方案。

这张图片相当粗糙,但特斯拉图片中的冷却板看起来很相似,因为它有很多入口和出口。水冷是这种功率和热密度水平的必要条件。
另一个引人注目的元素是似乎没有任何 HBM 或其他基于 DRAM 的技术。 与 Cerebras 非常相似,它们很可能采用完全依赖于芯片 SRAM 的设计。
虽然我们很高兴看到8月19日的特斯拉人工智能日会发生什么,但我们不会对这一芯片的具体细节过于激动。InFO_SoW只是一种猜测,尽管之前有一些传言称特斯拉、博通和台积电将合作将其产品化。谷歌与博通在其人工智能加速器的TPU系列上有类似的安排。晶圆上的系统技术(system on wafer)与集成扇出的结合可以实现惊人的人工智能性能,这是目前 Nvidia 和其他公司的 AI 加速器梦寐以求的。
此外几乎可以肯定的是,三星生产的下一个芯片将应用在他们的5纳米节点上。这看起来可能是一个完全不同的芯片,芯片面积更大、封装方式非常不同。上面的图片将无法进入大规模生产的汽车,而是在数据中心训练巨大的人工智能网络,然后用于汽车的自动驾驶。
